Valley of Despair
I chose a dramatic title because maybe it’s true…
Or not. I don’t know yet. I haven’t started.
After publishing the first chapter, I figure I’d take a break, and then I browsed around for a bit, felt guilty about not reading enough books, feel like nothing matters in that context most of the time anyway because I am an economic gollum, and then reflected upon how every action must have output is extremely intense and unnecessary sickness, some Mexican fisherman staring amused, but nevertheless, here we are. So let’s continue!
.jpg){kind=link}
Where did we leave off? Thus far we can create websites (no UI yet for the actual creation process, something to do), and from that we can open an “editor” and open and edit the files already created.
One thing we’re missing is the ability to actually create files in the UI, so let’s work on that.
Additionally, a lot of the React code is garbage, so we need to clean that up by separating out components.
Before we do that, we need to think about “who” owns the state. Right now we have the files listing “owned” by Inertia technically, as it passes down as a prop and we use it as a prop. If we want to add or remove files, that’d require inertia reloads as things stand.
So we also need to move the file list into the zustand store. May as well throw the whole scope in there, probably.
Hour of moving files around
Finally everything is cleaned up. I’m still thinking about how to exactly handle the hand off between inertia and zustand, but this seems good enough for now:
function toFileBuffer(file: SiteFile): FileBuffer {
return {
path: file.path,
savedContent: null,
unsavedContent: null,
status: "unloaded",
isDirty: false,
}
}
function Editor({ scope, files }: EditorProps) {
const setSubdomain = useEditorStore((state) => state.setSubdomain)
const setBuffers = useEditorStore((state) => state.setBuffers)
// Sync Inertia props to the store.
useEffect(() => {
const initialBuffers = Object.fromEntries(files.map((file) => [file.path, toFileBuffer(file)]))
setBuffers(initialBuffers)
setSubdomain(scope.site!.subdomain)
}, [scope.site?.subdomain, files, setBuffers])
return (
<div className="grid grid-cols-12 h-full">
<ExplorerPane />
<EditorPane />
</div>
)
}I also need more discipline in naming File vs Buffer which, while almost the same, isn’t really. It’s hard to say if we even need the type distinction between the SiteFile and FileBuffer to be honest. To clarify, a buffer is an opened text content within whatever program. Files are absolutely buffers, but buffers aren’t necessarily files, depending. It’s a word to clarify that the File you have opened in whatever document viewer isn’t technically the file on the file system, but loaded into memory, loaded into a “buffer”. This is unnecessarily pedantic, by the way.
I wonder if Buffer originated from Emacs or from somewhere older. That’s where I lifted the term from, even though I’m a putrid vscode user now. You eventually defect from the computed ideals when your tolerance to configure your code environment drops from several hours to a few minutes a year and you realize there’s no way you could ever rebuild all of the technological structure, blessed by TSMC finding the divine through nano-precision.
All you need to learn are the Emacs keybindings and make them work everywhere and you’ll never have to think about MODEs or anything else. Do my fingers hurt? Sometimes. But that’s from typing manic pieces online for how many years, literally slamming each key down as though if I broke the switches then the revelation will come, the point will be felt, I will be a god. Fear and trembling.
Anyway, The ExplorerPane is the same as VScode — that’s what they call it, that’s where the file tree is. EditorPane may be the same, not sure.
But this is a lot cleaner than what was there previously…
Okay, I wrote it like ten times now as a segue but let’s FINALLY create and delete files.
To do that we need a new route:
# lib/project_web/router.ex
scope "/api/sites/:subdomain", ProjectWeb do
pipe_through [:browser, :require_authenticated_user, :require_site_access]
post "/files/*path", FileController, :save
get "/files/*path", FileController, :open
delete "/files/*path", FileController, :delete
endThen we need to create a new context function and that :delete controller action.
First the context function:
# lib/project/hosting.ex
def delete_site_file(%Scope{} = scope, %SiteFile{} = site_file) do
with true <- scope.site.id == site_file.site_id,
{:ok, site = %Site{}} <- Repo.delete(site_file) do
{:ok, site}
end
endSo we have leaky authentication here. See the first line, scope.site.id? We’re using that to check if the user is authorized… as the assign_site_to_scope function we run in the router requires the user to have a relationship with the website (e.g. member, admin, whatever). The issue is that if we somehow change that requirement within assign_site_to_scope where it assigns the site.id no matter what, then this function is broken.
Something to keep in mind as we figure out permissions more.
We could’ve made it so it deleted by path, avoiding two database calls later on in our controller action. Something like this:
from(sf in SiteFile)
|> where([sf], sf.site_id == ^scope.site.id and sf.path == ^path)
|> Repo.delete()I guess we’ll do that. Let’s go to the controller action next:
# lib/project_web/controllers/file_controller.ex
def delete(conn, %{"path" => path} = _params) do
scope = conn.assigns.current_scope
path = Enum.join(path, "/")
Hosting.delete_site_file(scope, path)
Storage.delete(scope, path)
conn
|> json(%{status: "ok", message: "Successfully deleted."})
endI don’t think we need to handle failures here when deleting for now. Honestly Storage ought to be called from Hosting, but we’ll get to that in time. I don’t want to be so gung-ho about it, tie it together, only for it to make no sense and regret it later.
So now that’s wired up, we can add a delete button next to a file name. Ideally this would be behind a context menu you right click on to delete, but we’ll also add that later.
So first we need to add a button:
{allFiles.map((f) => (
<div
key={f.path}
onMouseEnter={() => preloadFile(f.path)}
onClick={() => openFile(f.path)}
className="... group ..."
>
<FileIcon className="size-3.5 min-w-3.5" /> {f.path}
<span className="ml-auto mr-1" onClick={() => deleteFile(f.path)}>
<XIcon className="size-3.5 hidden group-hover:block" />
</span>
</div>
))}And also create our deleteFile function within the store:
deleteFile: async (path) => {
const file = get().buffers[path]
if (!file) return
await api.delete(`/sites/${get().subdomain}/files/${encodeURIComponent(path)}`)
set((state) => {
const { [path]: _, ...rest } = state.buffers
return {
buffers: rest,
openOrder: state.openOrder.filter((p) => p !== path),
activePath: state.activePath === path ? null : state.activePath,
}
})
},That openOrder is for the small open tabs later at the top that a lot of code editors have. Even if I don’t use them myself, we’re not going to implement a fuzzy search anytime soon.
Also, you’d think we’d hold a reference to the activeBuffer, not the activePath, especially because objects are held by reference, but it’s better to avoid multiple variables pointing to the same references across objects when possible.
Sometimes it feels like JavaScript is unnecessarily verbose. I keep trying to rearrange it to make it more clear. Entropy usually wins.
Anyway, let’s also set up our create function. The way to do this is inline, like how VSCode does. So we need a new form input.
Something like this:
function FilenameEdit({ setShowInput }: { setShowInput: (value: boolean) => void }) {
const createFile = useEditorStore((state) => state.createFile)
const [filename, setFilename] = useState<Path>("")
const handleCreateFile = async () => {
await createFile(filename)
setFilename("")
setShowInput(false)
}
return (
<div className="ml-3 pl-1 group border-l border-gray-800 flex items-center gap-x-1 cursor-pointer text-xs text-slate-400 hover:text-slate-300">
<FileIcon className="size-3.5 min-w-3.5" />
<input
className="focus:outline-none focus:ring-0"
value={filename}
onChange={(e) => setFilename(e.target.value)}
onKeyDown={(e) => {
if (e.key === "Enter") handleCreateFile()
if (e.key === "Escape") setShowInput(false)
}}
autoFocus
placeholder="new-file.html"
/>
</div>
)
}And as for the corresponding createFile that’s just creating a new buffer, sticking it with the rest of the buffers, and then making sure our backend knows about it by internally calling saveFile.
We’ll need to add more validations here later. Like making sure an extension is defined, perhaps, or that just defaults to a text file I suppose. No spaces to make things easier, or maybe not. Not sure. Check the supported extensions too.
Anyway and finally, we only want to show or hide this input when someone clicks on the “add file” button. So all we need is some local state to do that:
export default function ExplorerPane() {
// ...
const [showInput, setShowInput] = useState(false)
return (
<aside className="flex col-span-2 flex-col">
{/* ... */}
{showInput && <FilenameEdit setShowInput={setShowInput} />}
</aside>
)
}Now we can create and delete files, albeit poorly. Eventually we need to migrate to a file tree, allow inline filename editing, etc.
Did you notice the flash there, after entering a filename? The only way to solve that, as far as I’m aware, is to migrate all the local state into the store itself. Or we’ll probably refactor it later so each tree node has its own toggle to an input. This works for now.
Okay, we can finally create and delete files. So now we can technically use this interface to create a website.
Let’s look back at the MVP…
Okay, so we completed check number 1, which is web file management.
The two remaining checks are site updates and actually showing the website. Actually showing the website seems like a small win, why not do that now?
Food break and aimlessness
All I have left is spite.
Anyways, let’s get that website spun up.
Serving & Auth ruminations
What needs to happen is that visiting <site_name>.app.local works.
To support that we need to, apparently, run our own DNS server so we can support wildcard mappings, e.g. *.app.local.
Fiddling for thirty minutes
Okay, we’re not doing that.
I will do the manual labor of adding websites to the /etc/hosts file. Maybe we’ll make a script later that lists all websites in the database to add to /etc/hosts later.
# /etc/hosts
# ...
127.0.0.1 app.local test.app.local test2.app.local
# ...By the way, the reason why I called this “Project X” is that it’s a placeholder until I buy a domain. You’re welcome to suggest ideas for what the domain should be, but I’m like ~90% sure I will choose one I have in mind. But maybe you have a compelling argument.
Three hours of research
So I ended up reading about security for a few hours. The reason why is because a common issue I see is the inability to set pages to private.
Wouldn’t you like to have private pages? It seems absurd… a little bit… but maybe not. Maybe you’re working on a draft. Maybe you want to have a scratch-notes area to figure out how things will look.
Whatever your reason, it’s nice to hide some things.
Unfortunately… if we were to ever support custom domains, this just simply wouldn’t work.
The strategy I came up with was to share the session cookie across all subdomains, which, at face value, sounds horrible, because then that means anyone could write a fetch request to the main site API with the visiting user’s credentials.
But if you set up CORS correctly, such requests would not be allowed. Phoenix comes with cross site forgery protection, too, as a redundancy.
In any case, it would’ve worked. You could’ve had some private pages.
But then we have those who like their custom domains. If you’re going to create a website… there are always those who want custom domains.
And now everything doesn’t work. Why? Because SameSite: Lax wouldn’t work for that. The session wouldn’t send.
But I just now realized I guess we could set two separate sessions on login per user. And then that’d work. And that wouldn’t be a security issue. Actually, it would, if this is multi-tenant.
Let’s say you have two users working on a website. Then someone configures the domain. If we make it so when both users log into the app now and they get a session for both urls, the person who owns the domain could set up a separate server, link it to some subdomain on the URL, and then if that user accidentally visits the new URL, their session would leak. Now the person who owned the domain can access their account.
I’m not sure if there’s a way to restrict subdomains by creating the session token somehow else…
But I guess there is. You could do an “authorize” hook on the custom domain website — would be a reserved route, like /auth — and then it’d only be restricted to the domain, not including subdomains.
So it all is very well possible, but there may be even another attack vector I cannot see.
So the question becomes: is all of this worth supporting private pages? I don’t know, I don’t have anyone telling me that they would, this is mostly conjecture. It sounds cool in theory. A more realistic option is to support the concept of a “draft” which can’t be seen by any user other than those in the editor. But I kinda think that defeats the point, because you want to see how your webpage looks, I think. Another example where having a session would be nice.
I guess private pages would be popular because you could have a “members only” section for those invited to work on the website.
Anyway, we need to set up two routers. If we detect a subdomain, then we go to the SubdomainRouter (which only serves websites, effectively), otherwise we go to the main router. This makes it so we don’t step on each other’s toes when it comes to pathways. Say for example you made /users/log-in on your website. Well, if I just stick this at the bottom of the current router:
# lib/project_web/router.ex
scope "/", ProjectWeb do
pipe_through [:browser]
get "/*path", FileController, :serve
endThe way the Router determines which route to go to is by going down the file. Higher up in the Router file is a route that matches /users/log-in so it’d just render the main website. Not a good look.
Several Hours Later
So the current auth model is there are two session cookies. The first will only be restricted to the main website. Let’s call this account_session.
The second will only be restricted to subdomain websites. Let’s call this role_session. The only “authorization” the role_session grants is the ability to see private pages, drafts, anything that has to do with the website as more ideas come in. The first feature here is private pages, of course.
The final piece of the puzzle is dealing with previews. If we have a website preview next to the code editor, well, we could just lower the role_session permissions enough that it’d be accessible through iframes.
But apparently Safari and at times Firefox(?) do not really respect SameSite: None cookies.
The solution is that we can throw a short-lived token within the preview URL that allows private page access. This token is generated and expires within the day, at least.
So here’s the new threat model: if you share a website with someone else, they own the domain, they set the domain, then they switch out the server and receive your role_session, well that doesn’t give them any power to do anything else. All role_session does is let the user access private pages on the website if it’s allowed.
Thus, the only real risk is if these short-lived tokens are leaked to those who were not allowed to view private pages.
We can try to see if SiteSame=None will work, or just maybe setting the auth to all subdomains, etc, we’ll see. For example, I think we could make the role_session scoped to all subdomains and that’d work just fine. I hope it works out that way because then we don’t have to deal with the tokens at all.
Three years of contemplation
I gave more thought and think having a shared role_session across all subdomains is too risky. So basically we’d have one role_session per subdomain, and you’d set up an “Auth” button your website to gain access to private content.
At the end of the day though, after researching this for a literal day actually, I’m heaving over whether to deal with the inevitable question of, “why could my friend see my private page” or something like that. I don’t want to be the reason someone leaked something embarrassing that was for their eyes only. I think it’s possible to pull this off, but I just don’t want to deal with that.
This is giving me an existential crisis on the whole point of building this. I mean, after all, I don’t even use the web editor. I’m some shmuck with a static site generator and upload through the CLI. Why am I building things I wouldn’t personally use? I don’t know. I mean obviously we’ll make a CLI, I just have a hard time believing there are people that use the web editor, almost mythical.
Anyway, the interesting idea here was to prevent excessive scrapping, scoping one’s website, I mean who the hell wants the whole Internet to see what you’ve been up to? Walled gardens are the current zeitgeist for good reason.
But alas, the security model feels like too much.
I do have a solution, though, I think, for drafts at least.
We’re giving up on the whole “private” aspect. But we don’t have to give up on “drafts” necessarily. We’re just going to rename it to “unlisted” pages.
So we’ll have a preview url and that serves all pages including the unlisted pages.
So let’s say you’re working on a new blog post. You can create the file, and label it unlisted. Or maybe it defaults to unlisted. In either case, you work on the unlisted page until you want to list it.
This solves a few things while also shirking responsibility. You technically get a “canvas” to work on, but it’s also understood that if anyone grabs your preview url, they can see it. No more thinking about auth either.
Pretty good.
We finally have a purpose behind the SiteFile struct: to determine whether a page is unlisted or not.
No more thinking about security.
The only thing left to think about, since we’re getting rid of fine-grained permissions, is to have the role_session represent whether or not you’re a member of project X. Or perhaps a follower. Or anything like that.
Instead of allowing some pages and hiding others, the role_session would essentially block wholesale.
Only followers can view it. Only a select few of followers could view it. Only anyone a part of Project X could view it, etc.
This isn’t private necessarily, but it is at least a defense against the hordes of random bots and smugglers of spice.
Your website can still get “leaked” by anyone in your followers, the same way someone screenshots a social media post, (except they can download the HTML page itself…) but nevertheless it’s something at least.
I still feel like this is no different than fine-grained permissions per file though.
I’m gonna have to do it, aren’t I? I feel like this whole endeavor was useless otherwise if we don’t add some permission model.
It’s like 90% likely I’ll end up doing this and deal with the customer rage.
Okay, we’ll put that off for now. Let’s serve the website.
First, we need to create a “dispatcher” that dispatches the router depending on the request domain:
# lib/project_web/router_dispatcher.ex
defmodule ProjectWeb.RouterDispatcher do
@moduledoc """
Routes requests to different Phoenix routers based on whether the request
is coming from the main domain or a subdomain.
"""
@behaviour Plug
import Plug.Conn
@impl true
def init(opts) do
config = Application.get_env(:project, __MODULE__, [])
opts
|> Keyword.put_new(:url, config[:url] || "app.localhost")
end
@impl true
def call(conn, opts) do
[domain, tld] = Keyword.get(opts, :url) |> String.split(".")
case String.split(conn.host, ".") do
[^domain, ^tld] ->
ProjectWeb.Router.call(conn, opts)
[subdomain, ^domain, ^tld] ->
conn
|> assign(:subdomain, subdomain)
|> ProjectWeb.SubdomainRouter.call(opts)
# custom domain, need to handle when we support
_ ->
conn
|> put_status(404)
|> Phoenix.Controller.put_view(ProjectWeb.ErrorHTML)
|> Phoenix.Controller.render("404.html")
|> halt()
end
end
endThe pin ^ operator inlines a variable and checks if it matches in the expected match clause, like in case.
Cool, now we need a SubdomainRouter:
# lib/project_web/subdomain_router.ex
defmodule ProjectWeb.SubdomainRouter do
use ProjectWeb, :router
pipeline :browser do
plug :accepts, ["html"]
plug :fetch_session
plug :put_secure_browser_headers
end
scope "/", ProjectWeb do
pipe_through [:browser]
get "/*path", FileController, :serve
end
endWe can later extend this router to include UserAuth and also add its own session details and such.
Finally we need to switch out the Endpoint.
# lib/project_web/endpoint.ex
defmodule ProjectWeb.Endpoint do
use Phoenix.Endpoint, otp_app: :project
# ...
plug Plug.Session, @session_options
- plug ProjectWeb.Router
+ plug ProjectWeb.RouterDispatcher
endSee the Plug.Session? We’ll need to include that into each individual router later on regardless of whether we’re doing permissions or not.
Alright, one last thing.
We need to create that :serve action.
Here’s a rough draft:
# lib/project_web/controllers/file_controller.ex
defmodule ProjectWeb.FileController do
use ProjectWeb, :controller
# ...
def serve(conn, %{"path" => path} = _params) do
subdomain = conn.assigns.subdomain
scope = Scope.for_user(nil)
with site when site != nil <- Hosting.get_site_by_subdomain(scope, subdomain),
scope <- Scope.put_site(scope, site),
file when file != nil <- Hosting.get_site_file_by_path(scope, Enum.join(path, "/")),
{:ok, content} <- Storage.load(scope, file.path) do
conn
|> put_status(200)
|> put_resp_content_type("text/html")
|> send_resp(200, content)
else
_ ->
conn
|> put_status(:not_found)
|> put_view(ProjectWeb.ErrorHTML)
|> render("404.html")
end
end
# ...
endAs we figure out the permissions for per-site that scope can include an actual user and restrict pages.
With all that said and done, let’s visit test.app.localhost:4000 and see if it renders.
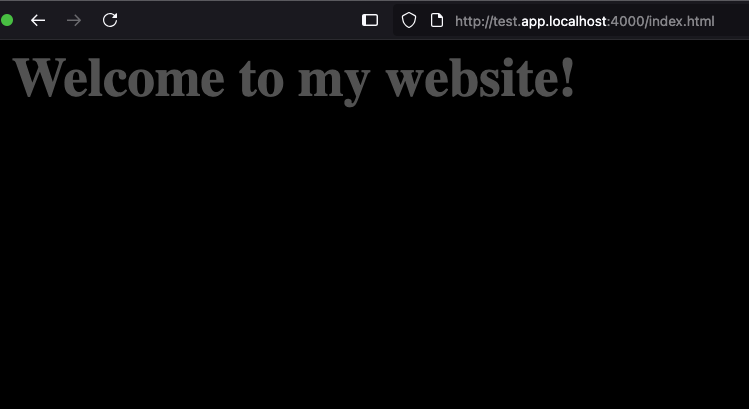
Great! Of course we’ll need to edit the :serve action to account for index.html but let’s put that off.
So now we’re serving the webpages created. That’s another check off of MVP (even though there is no way this is an actual MVP that could be deployed) so let’s do the last checkmark: site updates.
So we need to build out a feed.
Four hours of more research
I came across this pretty amusing idea which I will keep under wraps until we implement it. We need to clean up the base product first.
Anyway, let’s continue.
Closing the loop
We’re so close to our arbitrarily defined MVP…
We must press forward.
Here is our current MVP checklist:
- open an editor pane with your website, save
- create a
SiteUpdatedepending on timelapse - have a subdomain route to the newly created website
We’re going to break down this last goal of “feed/site updates”.
I could cheat here and just make this about implementing site updates alone (which I’ll end up doing), but we need to be more precise to genuinely check off our arbitrary MVP.
A user, if they follow a website, must see these site updates. We could’ve cheated with a global site update feed (to which, I do wonder, whether it would be of benefit to exclude…)
So we have a few items to wrangle:
- Actually build out some app UI, functional pages like website “profiles”
- Create a SiteUpdate dependent on some conditions when someone edits their website (to be improved upon later…)
- Allow users to subscribe to website updates and populate their personal feed
That should be everything we need. We’ll expand as more issues crop up.
Side note: do we want to have “user profiles”? I think it’s a must, probably, because how else can you figure out how to invite others to your website? You need to have some sort of profile search… but this is for another day. Actually, the elegant solution here is to let you build your profile: you cannot delete your “user” website which has your name. This website is where you will store all the things about you, and people can subscribe. I realized a trouble here though is handling subdomain clash between users and websites. It’ll be fine.
Well, for starters, let’s work on that UI. It’ll inform us of what exactly the “SiteUpdate” struct needs to look like, beyond our initial plan out back in chapter 1. It’ll also inform us if we need any new structs or tables and etc.
Let’s begin with the “Website Profile” page…
We need to add a route and render it, of course.
Two hours of UI spelunking
Okay, I think I have a vague idea of how it could look.
Obviously a good idea here would be to scaffold with Figma, but that’s okay.
Anyway, let’s add the route:
# lib/project_web/router.ex
scope "/", ProjectWeb do
pipe_through [:browser, :require_authenticated_user]
# ...
get "/sites/:subdomain", SiteController, :profile
# ...
endLater on we could make these site profiles available to anonymous users. I’m just throwing it under here for convenience.
Or am I? Why wouldn’t I make a walled garden? Do you think I’d throw that power away so carelessly? For every login popup so a new user waits… or it’s a wall to scale which keeps out the undedicated…
Anyway, let’s go make that :profile controller action.
# lib/project_web/controllers/site_controller.ex
# ...
def profile(conn, %{"subdomain" => subdomain} = _params) do
scope = conn.assigns.current_scope
case Hosting.get_site_by_subdomain(scope, subdomain) do
nil ->
conn
|> put_flash(:error, "That site doesn't exist!")
|> redirect(to: ~p"/sites")
site ->
conn
|> assign_prop(:site, site)
|> render_inertia("Sites/Profile")
end
end
# ...Right now the &get_site_by_subdomain/2 doesn’t even use the scope passed in. The permissions model currently makes little sense, but that’s okay. Hopefully it’ll make more sense as we continue.
Anyway, straightforward enough: if a site exists, let’s render the profile of it, otherwise redirect back to the directory.
Let’s begin making a Profile.tsx scaffold.
import { Scope, Site } from "@/types"
type SiteProfileProps = {
scope: Scope
site: Site
}
function Profile({ scope, site }: SiteProfileProps) {
return <main className="px-4"></main>
}
export default ProfileSo I did some UI sleuthing around and wondered how we could innovate on profiles. I have a couple of cool ideas for far in the future, but for now I think we’ll just change the layout a bit.
The site’s index will be front and center, and then the details will go down, and then the feed will be below it. That’s the rough idea.
So we’ll have to make a screenshot cronjob, too, as time permits…
Anyway, I first fill in the “details” section, with the header — or, in this case, the website’s name.
function ProfileHeader({ site }: { site: Site }) {
return (
<header className="">
<h1 className="">{site.name}</h1>
<a
className="flex items-center gap-x-1"
{/* we need to make this swappable with other URLs */}
href={`https://${site.subdomain}.app.localhost`}
rel="noreferrer"
target="_blank"
>
{site.subdomain}.app.localhost <ArrowSquareOutIcon className="size-3.5" />
</a>
</header>
)
}
function ProfileDetails({ site }: { site: Site }) {
return (
<div>
<h2>Created</h2>
{site.inserted_at}
<h2>Last Updated</h2>
{site.updated_at}
</div>
)
}Looks like we need to update the site serialization.
# lib/project/hosting/site.ex
defmodule Project.Hosting.Site do
use Ecto.Schema
# ...
@derive {Jason.Encoder, only: [:id, :subdomain, :name, :updated_at, :inserted_at]}
# ...
endAs well as the TS type signature.
// assets/js/types.ts
export type Site = {
id: number
subdomain: string
name: string
inserted_at: Date
updated_at: Date
}30 minutes of research
Handling dates is painful. But I’ll try out this “date-fns” library and it seems to work okay:
function ProfileDetails({ site }: { site: Site }) {
return (
<div className="">
<h2 className="">Created</h2>
{format(site.inserted_at, "d MMMM yyyy")}
<h2 className="">Last Updated</h2>
{format(site.updated_at, "d MMMM yyyy")}
</div>
)
}I realized that I need to update the updated_at of a site whenever its files change for easy access to sorting sites and also displaying this correctly. Otherwise, if we make updated_at only reflect updates done to the website metadata, well, I’m not sure how that’d be useful.
I added some edits, some classes, fixed up the default layout a bit, and then took advantage of CSS grid to lay out the rest of it:
// assets/js/pages/Sites/Profile.tsx
function Profile({ scope, site }: SiteProfileProps) {
return (
<main className="px-6 py-8">
<div className="grid grid-cols-1 md:grid-cols-12 gap-6">
<aside className="md:col-span-3">
<ProfileHeader site={site} />
<ProfileDetails site={site} />
</aside>
<section className="md:col-span-9">
<div className="shadow-md h-[600px] w-full bg-gradient-to-tr from-violet-300 to-cyan-900" />
</section>
</div>
</main>
)
}Cool, this is how we’re currently looking.

So now we need to fit in a feed of updates somewhere.
Ideally you just scroll down, but maybe the Site info stays fixed on the screen? That might look cool.
Let’s try that out.
Hour of fiddling with UI
One thing I tried to explore was having the big blown up screenshot as the “background” and you scroll over it with a gloss effect. It’s not out of the running, but it does feel a little tacky.
In any case, I was worried about the Timeline and how it’d look because ideally you scope your paragraphs to like ~80ch and it’d look wonky otherwise. But what I realized is that the text can go all on the left and then the screenshots for that update can go on the right. It’ll look fine.
Who knows, maybe we do the cheesy gloss scroll. Who knows.
But for now we need to scaffold a “Timeline update”.
I have a couple of ideas here: in fact, I think it’s partially also why I wanted to make this.
Two hours of fiddling and failed research
So here’s the rough idea. The only thing missing are comments underneath the “site updates” which I’ll dedicate another chapter to implementing.
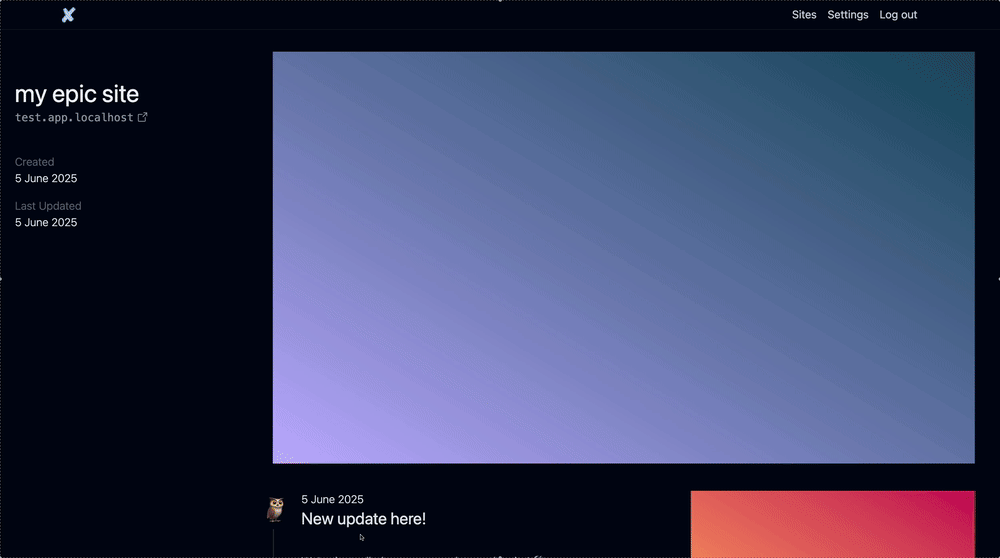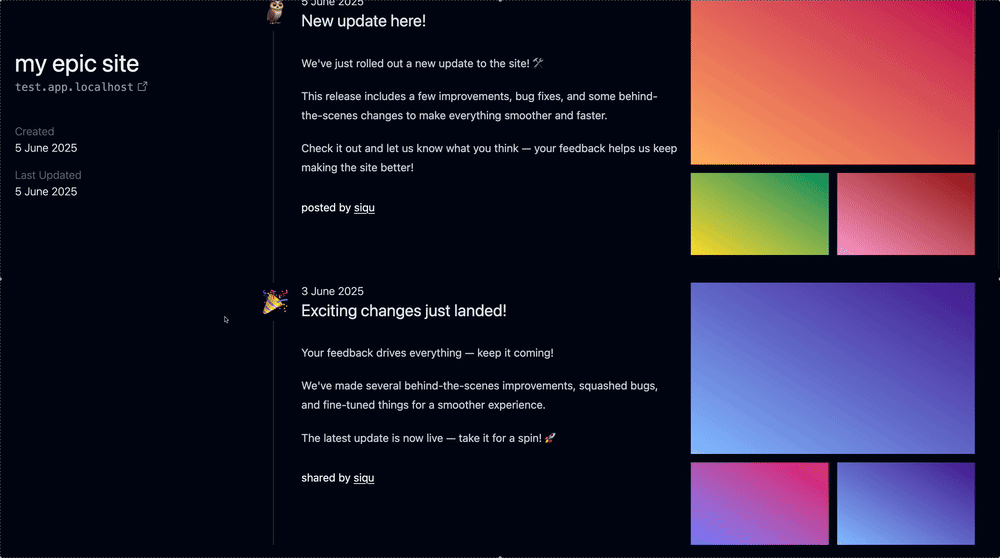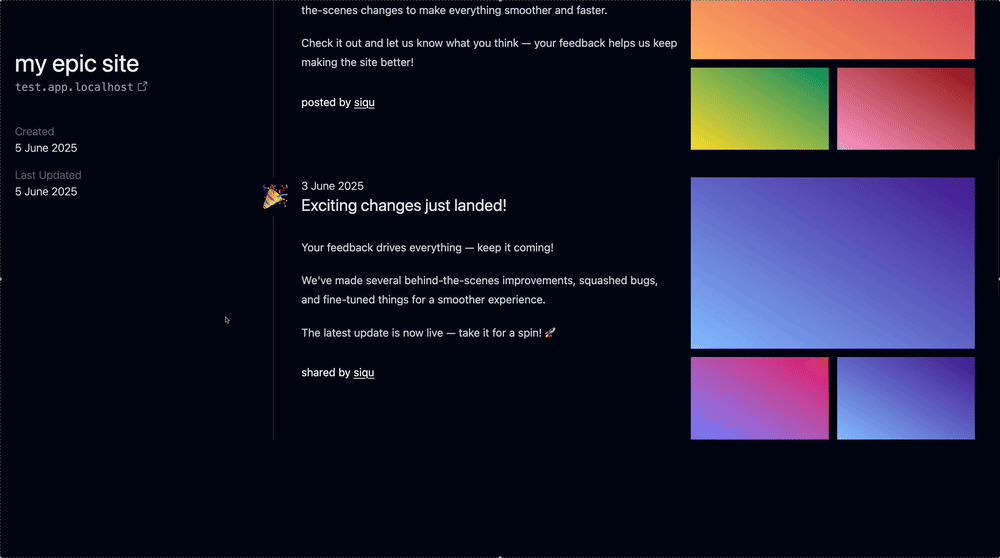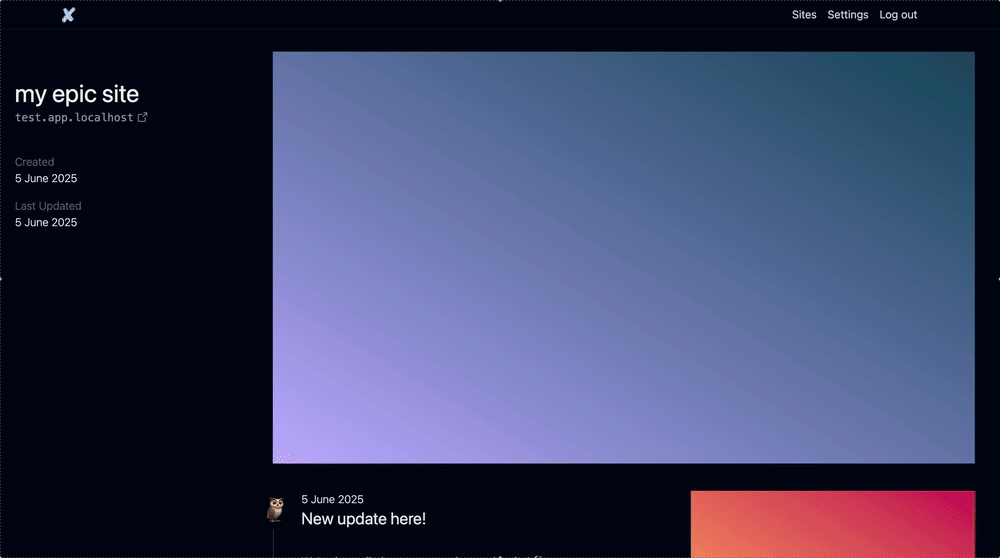
As for the comment, I think we’d just keep expanding the “site update” to accommodate. Additionally, there’ll be a “load more” button and hide excessive comments by default, I think.
I think this is all we need for what we’ll call SiteUpdate V1. From looking at the UI, we need a way to store a post, title, date’s already included, author because multiple users per site, though I guess that could be configurable?
Then we need to hoist the screenshots. I’m not necessarily looking forward to this one, because dealing with aspect ratio is always a little annoying. But it’ll be worth it.
Also, I would like to figure out a way to have more than just three screenshots showing. I guess they can be significantly smaller.
Looking at what’s next, now it’s time to build out the SiteUpdate.
Wiring in site updates entries
Okay, let’s generate the schema.
mix phx.gen.schema Hosting.SiteUpdate site_updates \
title:string \
emoji_code:string \
post:string \
site_id:references:siteI decided that the “author” part of the post isn’t needed on the SiteUpdate. It can be configurable on each website as to what to name the author “team”. So that’d be for later.
I think screenshots are out of scope for this chapter too.
Also, I think SiteUpdate has too much collision with the default column of updated_at. Are we updating the site, or how is the site updated, or are we updating the site update? Let’s change it to SiteEntry.
Here’s the migration:
defmodule Project.Repo.Migrations.CreateSiteEntries do
use Ecto.Migration
def change do
create table(:site_entries) do
add :title, :string
add :emoji_code, :string
add :post, :string
add :site_id, references(:site, on_delete: :nothing), null: false
timestamps(type: :timestamptz)
end
create index(:site_entries, [:site_id, :updated_at])
end
endWe want to have indices on both the site_id and the updated_at because we, in most cases, want to access site updates by the order. There are a few queries which could use site_id only, like checking the count.
We can always add an index on site_id later if we need it.
Here’s the SiteEntry.
defmodule Project.Hosting.SiteEntry do
use Ecto.Schema
import Ecto.Changeset
@derive {Jason.Encoder, only: [:id, :title, :emoji_code, :post, :updated_at]}
schema "site_entries" do
field :title, :string
field :emoji_code, :string
field :post, :string
belongs_to :site, Project.Hosting.Site
timestamps(type: :utc_datetime_usec)
end
@doc false
def changeset(site_update, attrs, _scope) do
site_update
|> cast(attrs, [:title, :post, :emoji_code, :site_id])
end
endCool, I think that’s everything.
So now we need to be able to create these (automatically). Because if I personally had to actually manually click a button to create an entry I would never do it.
To create a site entry on update, we need to hook into when a site’s files are changed. Or, more specifically, saved.
Let’s go back to the FileController and check out the save action.
def save(conn, %{"content" => content, "path" => path} = _params) do
scope = conn.assigns.current_scope
path = Enum.join(path, "/")
case Hosting.get_site_file_by_path(scope, path) do
nil -> Hosting.create_site_file(scope, path)
_ -> :ok
end
:ok = Storage.save(scope, path, content)
conn
|> json(%{status: "ok", content: content, message: "Successfully saved."})
endWe need to modify the functions in here to update the file, the site itself, and also create/modify a site update.
It seems inevitable in programming that you’ll come across a knot or just something that is disorganized, has no hierarchy or sense, like in this current case.
This controller action code is already pretty bad. Then you open up Hosting and see scope scattered everywhere but not used correctly. Your auth paths aren’t clear, it seems like you should access site within scope but you aren’t because scope isn’t existing, etc.
But I think it’s the same as cleaning a room. You grab one thing at a time, move it, do it again. Eventually things will click into place.
So, the first thing is actually updating the site file. Because we aren’t doing that currently.
So let’s do that:
def update_site_file(%Scope{} = scope, site_file) do
now = DateTime.utc_now()
site_file
|> SiteFile.changeset(%{}, scope)
|> Repo.update!(force: true)
from(s in Site, where: s.id == ^site_file.site_id)
|> Repo.update_all(set: [updated_at: now])
maybe_create_site_entry(site_file.site_id)
endThis is also a great time to update the site’s timestamps so we can sort and reflect the last edit time of a site. We need to do force: true in order to update the site file because we’re only changing timestamps.
Lastly, we might need to create a site entry if we haven’t published a site entry in a day, so I added the stub in there.
But as I started to write out the maybe_create_site_entry stub I realized a critical error.
Let’s say we want to have 24hrs cooldown between updates. If we rely on the site_entries table to determine if the cooldown has elapsed, users can no longer “opt out” of site entries by deleting them when they’re created.
Because every time you delete the latest SiteEntry, the next file save will just create a new one. Because it doesn’t know you already deleted one; the “latest” SiteEntry in the site_entries will be from like 3 days ago.
So we can’t rely on the site_entries table to determine the cooldown. We need to create a new field on sites:
defmodule Project.Repo.Migrations.CreateSiteEntries do
use Ecto.Migration
# ...
alter table(:sites) do
add :cooldown_until, :timestamptz
end
# ...
end
endAnd after we add that to our Site struct:
# lib/project/hosting/site.ex
defmodule Project.Hosting.Site do
use Ecto.Schema
# ...
schema "sites" do
# ...
field :cooldown_until, :utc_datetime_usec
# ...
end
# ...
endWe can now easily determine whether to create an entry.
# lib/project/hosting.ex
def update_site_file(%Scope{} = scope, site_file) do
now = DateTime.utc_now()
site_file
|> SiteFile.changeset(%{}, scope)
|> Repo.update!(force: true)
site = get_site!(site_file.site_id)
cooldown_expired? = cooldown_expired?(site, now)
if cooldown_expired?, do: create_site_entry(site)
attrs =
if cooldown_expired?,
do: %{cooldown_until: DateTime.add(now, 1, :day)},
else: %{}
site
|> Ecto.Changeset.change(attrs)
|> Repo.update!(force: true)
end
defp cooldown_expired?(%Site{cooldown_until: nil}, _now), do: true
defp cooldown_expired?(%Site{cooldown_until: cooldown}, now), do: DateTime.after?(now, cooldown)One of the cooler parts of Elixir shilled by every Elixir person ever is “pattern matching”. In this context, you can “pattern match” on function calls. You can think of those cooldown_expired? compiled into a case statement.
I honestly think this looks pretty bad, again, but maybe it’ll look better in time. We’re calling Ecto.Changeset directly because we don’t need to run validations on what we’re doing here.
The main thing I don’t like is up to four database calls: one to update the site_file, one to fetch the site, one to create the site_entry and one to update the site. I guess they could all be wrapped in a transaction later.
But yeah, now we can check against cooldown_until. If we’re past the timestamp recorded in cooldown_until then we can create a new one.
Again, we probably should get site from the scope. So we need to figure that out.
I think we’ll figure out all the scope and permissions stuff as soon as we start playing with multiplayer stuff.
Great!
One thing in the back of mind is how we’ve written absolutely zero tests. Part of the reason though is that I’m still not sure what functions we’re keeping or which we’re discarding.
The Hosting context has a bunch of functions we haven’t used. I doubt we will use them. Additionally, the “barriers” or “auth contexts” are still hazy. When am I allowed to fetch a site? When am I not? It’s obvious when we’re asking about editing files, but that’s the only one where it makes sense.
So let’s just procrastinate making tests until things are more clear and we clean out Hosting.
Anyway, with that done, let’s create a %SiteEntry{} and get rid of the filler data…
For the next chapter. We’re around ~6k words and the first chapter felt way too long.
Recap
What did we accomplish thus far?
It doesn’t seem like much, but it slowly comes together. A lot of research it seems. Basic UI. Serve a user website, finish up the basic file stuff. Agonize about how to handle authentication. Half of the stuff we’ve written thus far for SiteEntry hasn’t even been tested.
In the next chapter we will finally check off creating site entries in a most barebones form. There are always addons we can tack after.
After that’s accomplished… a lot of work needs to be put in the editor. Either that or begin to see how the application feels with more than one user. Handling permissions too. The current form of SiteEntry is quite lacking, as is the website profile page.
But I think making the editor experience better would be the most amusing. Would it be cool or horrifying to see multiple cursors blinking and typing on the screen?
We’ll see.