Dogfooding
So the current objective is to run webnook push dist/ and have everything show up, working properly, at siqu.webnook.org.
So we need to make a CLI that uploads a directory. Then wire up ingestion on the server. And because I didn’t like having NodeJS on the server, I’m restarting the project. “Restart” sounds egregious, but it doesn’t take much effort to migrate files. Slowly the rest of the work (or at least what’s desired) will migrate over to the new codebase, after CLI uploading is working.
As of today I only need to copy over some resources (Site, SiteMembership, SiteFile) and then the Storage.
But there were a few things that were wrong with the previous implementation anyway.
Prior Qualms
For starters, you definitely don’t want to store files and directories as :path alone. It makes sense for fetching the file, but dealing with directory deletions and renames is a headache.
On top of that, you don’t necessarily want mutability when it comes to editing. Race conditions and everything, and saving progress, etc. There are a lot of cool features hidden behind immutable blobs (which is how Dropbox and friends work).
Additionally, in the last iteration, I wasn’t too happy about how Scope was working and what was in it.
So all of these will be fixed, mostly.
One thing that was bothersome last time we touched this code was dealing with local domain resolution.
Since we’re dealing with subdomains one can’t naively use localhost.
So after messing with Vite config and dnsmasq we can now locally visit nook.test as well as siqu.nook.test and it all resolves properly.
You may be wondering what we’re using instead of InertiaJS… I know the curiosity is killing you. After much deliberation we’ll be using Unpoly and SolidJS. I’m curious to see how Unpoly compares to other solutions (htmx, hotwired) and Solid makes more sense when you’re dealing with codemirror (and potentially prosemirror) because both libraries have their own lifecycle which conflicts with React.
Random Constraints Soon Scrapped
After running the auth generator and modifying the %Scope{} to later accept anonymous users1 instead of remaining nil, I updated the %SiteFile{} schema and added a %Blob{} schema. This is either a typical case of overengineering or the start of something wonderful. You’ll see how this data model works as we continue.
The next steps are creating a site on user registration, perhaps adding a :content_source --- the point of this is to declare whether a site will be managed externally or internally. The fact is, since I am a CLI user, I rarely if ever use the site editor. There’s no point in me even opening it up, because if I want to make persisted changes, well, they won’t last unless they’re within the SSGs grasp…
Though after a bit more thought I decided to scrap this. If, for whatever reason, you upload generated artifacts through the CLI and yet desire to edit some pages too, who am I to say? It won’t be practical, it won’t make sense, but maybe it does make sense…
So, on with it, toward site creation at user registration. You have your personal site, and then all your other sites. Your personal site is bound to your username, should you change it. There are a bunch of small differences between a “personal” site and a “regular” site, so it’s probably for the best to take note of it with a new column. You could, of course, always derive it by checking username == subdomain but that seems a little impractical.
Naturally whenever you add a boolean to a database you would be wise to wonder if you can turn it into an enum. I suppose other site types would be :global, :template --- though I think templating would be more granular(?). The global type is where there can be a wiki.webnook.org and anyone can edit it. A more amusing idea would be saga.webnook.org or genesis.webnook.org and people LARP it up as historians & mythbuilders, didn’t I already write about this though? (Anyway, perhaps one could nudge the 1% rule to a 3%, though unlikely).
Whatever, let’s just make an enum of :personal & :regular. Update the migration file too… and the flashes are now working through Unpoly instead of the LiveView defaults.
Actually Doing Work
hour later
So to make sure usernames & subdomains are globally unique we need to create a :subdomains table and reference them on the site and user. And so when a user is signing up, we first check global uniqueness of the username, and if it works out, then we can finish creating the user and the personal site.
few hours later
A lot of random changes, nothing significant to report on. Need to update the tests and we’re about… 30% of the way there to dogfooding, I think. The big hurdles waiting are the b2 adapter and the CLI. Right now it’s a slow sand-gathering, of all that we need to make the glass remaining. That’s what happens when you completely change the architecture again.
Reflections on Programming
Sometimes when you get to program long enough, well, it’s a stark contrast to writing on here. But at least with programming I feel like, for once, I am carving into something. If writing pseudonymous letters counts as shallow stick drawings the waves lap at and disappear in a few evenings, then programming is sincerely that castle, not in the sky, of sure sand instead, bolted right next and even though the waves will consume it, well, you can at least look at it for a bit longer.
It does feel like creating a tombstone, in a way. I already see the website as abandoned, the buildings half-standing. Clicking on webpages while the HDD whirrs before it inflicts data corruption. Break the tavern doors and dodge all the shards of pints, newspaper termites, and let me up the stairs, vaulting rotted gaps, til ensconced in cobwebs at the end of the second floor hall. So it creaks and while the fog sets in to consume the rest of the town, some thin silicon glow, well, what better place to fall asleep? Because my head is all screwy; I still hear the patrons and all their spirits animate around me.
This is all one can want.
Modeling SiteFile Properly
day more
Most of the day was spent on modeling file creation, probably. Had to rewrite the storage adapter, mildly. You’d think something so seemingly simple as a filesystem wouldn’t be too much.
def put_site_file(_scope, site, path, opts \\ []) do
Repo.transact(fn ->
{:ok, blob, contents} = ensure_blob(path, opts)
site_file_with_parents = site_files_from_path(path, blob)
site_file = upsert_site_files!(site, site_file_with_parents)
site_file = %{site_file | contents: blob && contents}
{:ok, site_file}
end)
endThis is the function to use, when we start uploading. It’s missing authorization, but I’ll wait until these functions are being referenced in controllers/dealing with the outside world.
Anyway, as you can see something as simple as uploading a file requires a rigid model. Modeling tree structures in Postgres can be interesting, and after much research I settled on parent_id referencing.
%SiteFile{} can be confusing because it can be a :file or a :directory, which is why we can have is_nil(blob) and is_nil(contents) and you have to handle that. It could be renamed to %SiteNode{} for clarity, but hard to say. I like “SiteFile” because a website is made of files. The “directory” seems like a mere implementation detail where you think of it that way.
If everything goes right, the next day shall begin with creating an API token table, wiring all that, adding the upload endpoint. Once that’s all working, then I’ll need to finish out the BlobStore… and add a few other restrictions.
I have this separate todo list but it does feel like fog. One little todo can end up being a ten layer dungeon… you can only predict so much on what’ll happen next.
Rendering User Websites
day later
I think we’re about ~50% of the way done. I hope I can finish this… this weekend, perhaps. Sometimes I get autistically fixated on the best way to model a function. I don’t know. Maybe it’s a way to feel in control, for however long that lasts before accepting everything turns to wire mesh.
In any case, after porting over more controllers and adding more tests, setting up a separate router for user sites, the index.html of the newly created website of a newly registered user is now rendering in my browser. Of course some basic UI is missing to indicate the shape of the site and whatever else, but we’re pooling all resources to devote towards The Demo.
The Demo is being able to upload this site and have it all work. Sometimes I feel weirdly ironic… you can probably guess I don’t want this website to be anything more, to have anything more than what it is. I like the idea of creating a dead website hoster to host my dead website.
You may think it doesn’t make sense, but do you ever think about the beauty of obscurity? Were you ever an admirer of anything? Then you watch everything you love get disfigured from the sheer weight of eyes on it, sapping the sources of good-honest careful cultivation and fondness. In the ruins of the Content Beam my legos got all melted together, and honestly, I know it’s all crazy, but it is precisely in the corners of the wasteland where it’s best to build a shelter. Otherwise the scavengers will piece it apart, and pull you apart, and then you learn to scavenge too. Being wellknown means dying.
Anyway I guess we can just reuse the user_token table, slightly modified, and begin our CLI & API.
Obviously the API should be done first, but I find working in a different language mildly novel enough to switch over.
Golang & CLI Magic Links
day later
After adding “api tokens” as a concept to user tokens, outlined by the Phoenix guides, I wondered how to best facilitate logging in.
The whole “magic link” stuff is interesting… and can be implemented in the CLI, too. It took a bit to figure out how to model it without creating a new postgres table. But if we exploit whether the token is inserted into the database or not, we can distill this authentication down to two calls.
few hours later
I ran into some issues understanding how sessions persist across conn in testing. Also, after building out all the parts, it probably wasn’t the wisest idea to make one large integration test. Mismatching the routes, etc. but oh well.
For the CLI we’ll use golang because there’s no reason not to.
const defaultHost = "http://nook.test:4000"
func NewLoginCommand() *cobra.Command {
return &cobra.Command{
Use: "login",
Short: "Login via CLI",
RunE: func(cmd *cobra.Command, args []string) error {
fmt.Println("Starting CLI login flow...")
client := api.NewAnonymousClient(defaultHost)
if err := login(client); err != nil {
return err
}
fmt.Println("Successfully authenticated.")
return nil
},
}
}
func login(client *api.Client) error {
tok, err := generateCLIToken()
if err != nil {
return err
}
url := fmt.Sprintf("%s/users/log-in/cli", client.BaseURL)
fmt.Printf("\nPress Enter to open %s in your browser...\n", url)
bufio.NewReader(os.Stdin).ReadBytes('\n')
browser.Open(fmt.Sprintf("%s?token=%s", url, tok))
fmt.Print("Waiting for authorization")
apiToken, err := client.PollCLIAuth(tok, 2*time.Second, 5*time.Minute)
if err != nil {
return fmt.Errorf("polling error: %w", err)
}
return config.SaveAPIToken(apiToken)
}This is the meat of the login. I’m not so familiar with golang conventions, so if it looks rancid you know why. Anyway, the CLI login seems to be working.

Is it secure? Well, if someone else hands you a url, you click on it, click “Authorize CLI” and then they authenticate against it, then that’s that. A way more secure model would probably involve more backend tables and the like, but I’d like to think the current expiry works well enough. Actually, I should probably bump the expiry down to 3 minutes…
Anyway, we’re at the home stretch here. Now we just need to build the ingestion point, and then wire up the cli command.
Here is where we can begin with an innovation. Instead of attempting to upload each file, you can have a “handshake” which lists all of the file paths and their respective sha256s. Those that have the same sha256 can be skipped. Additionally, the upload can be parallelized. Finally, a summary can be printed of what was uploaded or not. These are all nice-to-haves, and maybe the first thing will be implemented, but we’ll see.
day later
Alrighty. The entire flow is now working.
After logging through the CLI through the magic link, you can run webnook push <dir> OR webnook push single/file.html and have it upload.
I’m thinking of the UX more, but I think for webnook push dir/to/file.html, we’ll default to removing the first directory if the remote is not specified. e.g. it’ll resolve to to/file.html on webnook, maybe.
I think for webnook push dir/ you can also specify the root remote directory, e.g. webnook push dist/ --remote blog/ if you have a static site generator for your blog posts. Maybe this isn’t necessary.
But finally, the full flow is working.
Now we need to wire up b2 backend, glue together the current repo toward prod (maybe actually use ansible this time for provisioning…), and then I can run webnook push dist/ and have siqu.webnook.org.
Perhaps it’ll be done today… depending on how difficult it is to wire up b2. I don’t think it’ll be too difficult.
few hours later
I beefed up the webnook cli to support both --relative-to and --remote.
So if you run
webnook push dist/blog/ --relative-to dist/it’ll preserve the blog/ in the path.
And if you have something which only outputs blog posts into dist/ then you can run
webnook push dist/ --remote blog/to make dist/first-blog-post.html be blog/first-blog-post.html on your webnook.
I think in terms of CLI UX we’re ~50% there. Maybe --relative-to ought to just be --root. We still need to add progress indicators, a summary too.
Also do the handshake diff I talked about earlier, to avoid attempts at uploading things that don’t need uploads. If someone has a better CLI design inquiring minds want to know…
But I suppose the CLI is fine for now.
Now it’s time to wire up the backblaze like I said I would for at least 3 months now.
The Backblaze Mini Chronicles
It’s tempting to just stop here and delay the backblaze wireup and production to the next chapter, but I don’t want this seeming curse to keep following me. I’ve been saying I’ll wire this up for at least four months now.
Luckily the wiring up process is easier because we’re dealing with immutable blobs. We don’t have to track relative paths, movement, renames. No song and dance of “looking inside” the file to see if we need to update it: we just look at the sha256.
So theoretically, the implementation to the BlobStore shouldn’t be more than 100 lines. Especially if we use some other library.
hour later
And it looks to be the case, though I’m cheating since I’m using a library. Nevertheless, the module is small enough to fit on here:
defmodule Nook.BlobStore.S3 do
@behaviour Nook.BlobStore.Adapter
defp new() do
config = Application.fetch_env!(:nook, :blob_store)
Req.new()
|> ReqS3.attach(
aws_endpoint_url_s3: config[:endpoint],
aws_sigv4: config[:keys]
)
end
@impl true
def save(blob_key, content) do
{:ok, _response} = Req.put(new(), url: "s3://nook-dev/#{blob_key}", body: content)
{:ok, content}
end
@impl true
def load(blob_key) do
{:ok, response} = Req.get(new(), url: "s3://nook-dev/#{blob_key}")
{:ok, response.body}
end
@impl true
def delete(blob_key) do
{:ok, _response} = Req.delete(new(), url: "s3://nook-dev/#{blob_key}")
{:ok, blob_key}
end
@impl true
def exists?(blob_key) do
{:ok, response} = Req.head(new(), url: "s3://nook-dev/#{blob_key}")
response.status == 200
end
endA total of 36 lines.
Yeah, I’m not too happy about how the functions look either. I’m not sure if the exists? one works, actually, since there’s nothing in the codebase using it. Same with delete, but why wouldn’t it?
After running webnook push test/ it all uploaded and after visiting first.nook.test the “first” website serves everything that was uploaded.
The response time jumped up from ~5ms to 350ms… so that’ll be fun to optimize.
I probably should write some tests…
But maybe this is the ultimate appeal of this platform. The jank factor will be so endearing that people can’t help but sign up for it. Although I was thinking of making it an invite-tree instead of random signups. You can always start with “invite-only” but once you remove it, it’s gone forever… Though I also acknowledge “invite-only” may be a horrible idea. And yet how else can one avoid being vultured?
Taking Inventory
There is a bug in the upload mechanism, and then maybe I need to learn how to stream the file? No, because some files I will need to process on the server anyway. I think I can set up a redirect, probably, depending on the blob type. But such optimizations are for later.
Well, everything is wired. Vaguely I suspect more than a few bugs if I uploaded everything, but why not give it a go? I will first test fully uploading this website using the Nook.BlobStore.Local adapter, and if that works, then try it out with b2.
Oh, I need to add another command for linking a working project directory to whatever website you’re working on, too. Added that to the todos.
And it works:
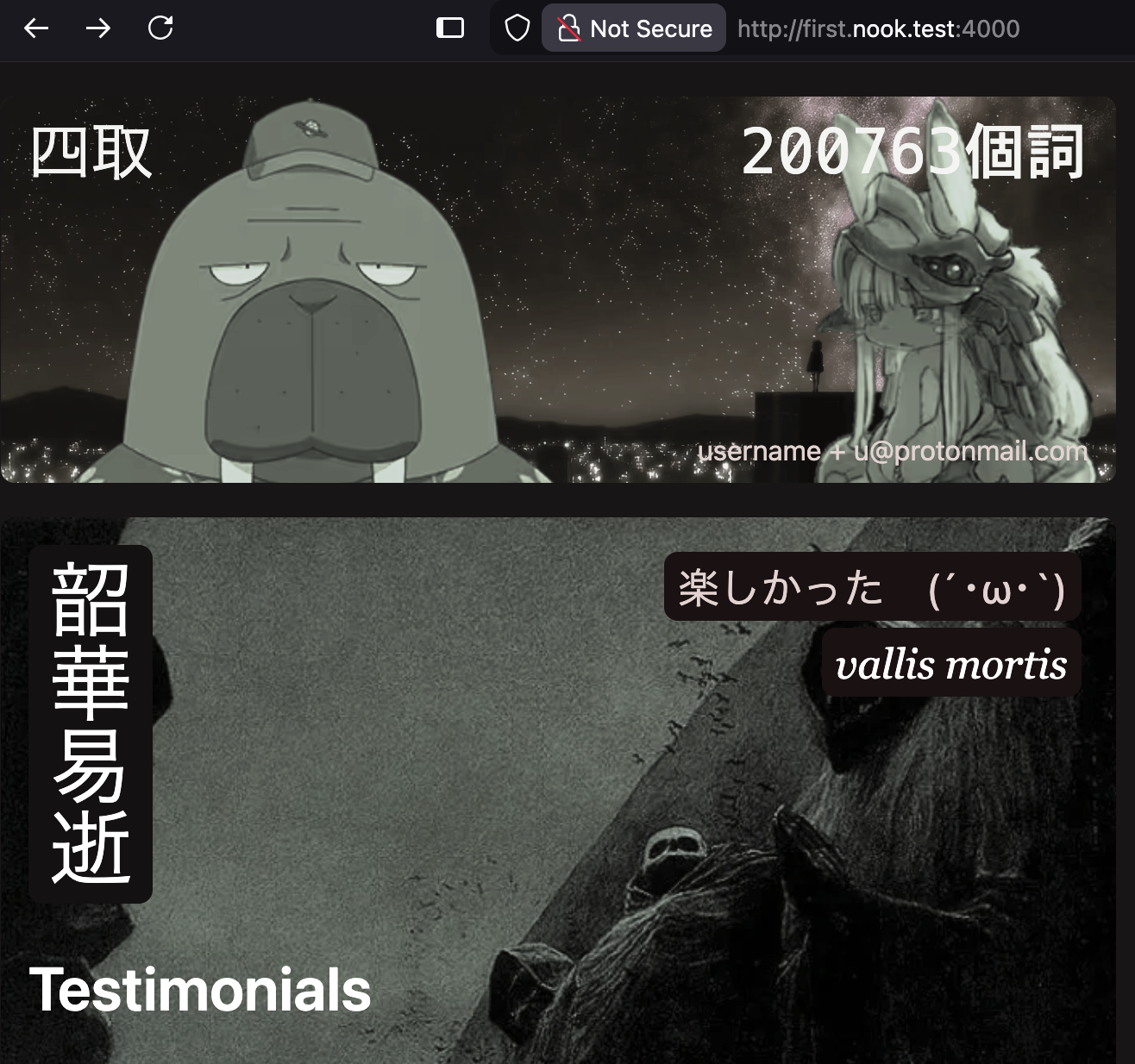
Everything being served in the above image (the css, pictures, JS) is persisted through long sha256 filenames. One could say the directory and hierarchy is entirely “virtual”.
Now it’s about ironing out the upload process. For example, I came across some race conditions by doing this test site upload. If two paths are uploaded and share a parent, that parent may be inserted twice. I think we just need to change how it’s inserted instead of throwing.
We need to create a webnook bind command which makes the current working directory bound toward a site of your choosing. This’ll generate a .webnook/ config directory, which can be expanded upon if needed.
The upload process in the CLI needs some spacing, some progress reporting. The CLI still doesn’t take advantage of doing a diff with the current backend site, yet.
I’d like to add some tests to the CLI somehow, too.
Finally, the actual website itself needs some small UI changes, the same as the last one probably.
The burning question is whether to mark this as the end of the chapter, or go for broke and have siqu.webnook.org up and running…
But realistically, even if the CLI was polished, race conditions accounted for, I still need to waddle through how I set up the server last time AND design the actual UI behind the login. Both shouldn’t take long though. Maybe I can do it all here. I’ll give it one more day.
It is quite the phenomenon, how distant the amount of work and then perceived output. I guess it’s like watching an episode of anime, isn’t it?
Most of modern life magic is obscuring how many man hours were put into it. Putting in way more than you would ever consider reasonable.
How cool would it be though to just post on webnook instead though? The servers will be fashioned up in Siberia, a new Arctic Vault for all the disillusioned and reaching.
Anyway, I’m trying to think of a reasonable demo to reach for, now that I see siqu.nook.test rendering.
Obviously I’d like to deploy this as soon as possible, but I also wouldn’t mind exploring unpoly + solid.js before committing to it, right?
So maybe the next cool demo is porting over the editor. And make it look nice! Then we can decide whether unpoly + solid stays. Though I wouldn’t be sure of the alternatives.
Yeah, the more I think about it, the more likely I’ll just keep working on this without updating the website. Living in Siberia!
Through the Sludge of Tartarus & Colorschemes
I want a screenshot that looks good. All of the previous screenshots of the editor looked scruff. It’s going to look as clean as possible. it has to be done. I will pop veins getting pixel perfect, unlike this current website. You know what they say about the cobbler…
day later
So I think the strategy here is to just lift what I did on the previous site and fit it into server-side templates. Once that’s migrated, along with the multiplayer, then the previous repo can be scrapped, I think. Hopefully by lifting the previous elements it won’t be too hard to give them a face-lift in the process.
few hours
I got locked in that race condition earlier. After reevaluating my options, I realize the best strategy is to just accept the failure and fetch it for now. The only case where that’s bad is if a file was being uploaded and it needs a new blob ID. Probably will have to rewrite it later.
few hours
I’ve been reading up on Postgres conflicts. It looks like you can’t have multiple constraints to target, and I tried alternatives, but it all results in a higher average of queries to the database. So I tried dealing with the current system as is, and was able to add enough branching to resolve this case, but this is clearly all wrong.
Yeah, I think the issue is how brittle site file ingestion is.
We can distill the two unique constraints into one by normalizing the path and stop cheating, basically.
e.g. instead of dir/ it’ll be dir. I mean, after all, this is why we’re storing the :kind type to begin with.
So before this is Deployed™ we’ll need to stop relying on ending slashes.
That’ll clean up the put_site_file stuff tremendously, and properly exit if other constraints are violated (such as empty filenames…)
This’ll also remove the :name field as we don’t need it anymore.
I think the plan is to wait until we’re doing actual file operations in the editor to see how it shapes, but I think we’re definitely normalizing paths.
Oh well.
I wish I could play some WarCraft 3 right now. Play some old techno and derezz into the brightly colored minimaps. Tower defense. Tron on StarCraft 2. It’d be cool to go to a LAN party… back in the 2000s. Why weren’t we together on WoW launch day? I wish I could disappear into endless ambivalence. I can feel my soul disintegrating. I don’t have a soul.
Anyway, let’s port over the horribly constructed Sites Dashboard and friends from the old website. Maybe just bite the bullet and work on the editor to iron out how site files will work. Ideally I could just deploy it after fixing the data model behind site files. I mean, b2 works and all. Oh well. Just wait until tomorrow, probably.
day later
Today was spent toward the Branding™ and Logo™, though it’s rather plain and obvious. Nevertheless I like the single-color simplicity of it, so let’s just file it as v1. Need to convert the font, too, into an SVG, for later.
After cleaning up the root and beginning on the navbar, now it’s time to yoink the previous implementation. I’m thinking a “Your Sites” title, and then a list. It would be cool to have a screenshot of the index of the site, but that’d probably require a separate service.
Hour research
Yeah, I guess a small node script would work there. For a very short now we’ll just do the Google Strategy, aka take the first letter and add a random color.
hours intermission
I ended up looking at alternative UI design and such.
another hour
Web development is a vortex…
I’ve still not ported the code over, so let’s just get it over with. Copy paste!
hour
So I’ve ended up scrapping the unnecessary and separate subdomain table. Some things sound nice on paper but when you actually start using it you can’t help but wonder how it ever sounded nice on paper. That you’re delusional.
Anyway that’s all fixed, and now the extremely low-effort “home” has a “Your Sites” with the low effort site card. I’ve been browsing around for the bleeding edge designs and thinking about how to design the “root” of a logged in user. Obviously it could default to a feed, but I don’t know.
Anyway, developing the UI helps see which parts of the data models are delusional. So next up is porting the editor. After that, probably normalize path files. And may as well have the same extremely basic Lua runtime from it. Then the old repo is done.
But after looking around, I might have better luck reimplementing it from scratch than to “port” it. Maybe even take on a custom collab experience…
day later
I ended up doing more research on removing the YJS dependency, and then how to make the editor look nice. But I really need to go back to the basics and implement the simplest of operations the editor will do. One those are implemented, then all of the current kinks in the data model are mostly sorted out, and then deployment can happen. That’s the idea, at least. So I guess we’ll narrow it down to the file tree and load the file in codemirror.
After looking through all of the React code I’ve decided to start again, essentially.
hour later
There’s like three things I want to work on concurrently because each piece would be painful to refactor later, but maybe it’s inevitable to refactor anyway.
Instead of having some “deliverable” this chapter I’ll just publish this and begin once more.
But how would it be to cap off the chapter with the preliminary objective!
Just get it done!
Singleplayer editor (for now…) and fix up the file data models.
It’ll look bad at first, too, and that’s fine too (don’t think I’m opening sign ups just yet post siqu.webnook.org working (not to imply anyone needs to use this service anyway))
day later
Fixed up the site file pathing. Now just need to work through bits of the editor… The trick is to begin with the glue of the backend, I suppose.
hours later
It’s live. https://siqu.webnook.org/
I just uploaded it and am now typing the rest of this.
I’ve decided to push the editor and all that entails for the next chapter.
Somehow the bundle size for app.js is far more than I expected. So that’ll be fun to optimize too.
The signup still does not work, because I want to finish out the internals of the editor and fileview --- the site is essentially useless except for the few that do use a CLI, but even if you did, the loading times are horrendous at the moment. Will require an application cache and CDN magic.
But yes, the website is now loaded in.
I think the overarching goal is to see if it’s feasible to reimplement this website purely through what Webnook™ provides, rather than using a static site generator.
But in terms of the next cool demo, I think getting the editor and file tree fully working and looking good will be what’s next. Optimizations can happen after. As otherwise this project is dead-on-arrival, not that I’d mind that anyway.
I’ll see if there’s an even cooler demo to target next… but that’s that.
Oh yeah, since I had to recreate the database, the previous “first website” was taken down. I saved the HTML and will snag that subdomain (test) and put it back up when the UI supports creating more sites.
Until next time.
Footnotes
-
How cool would it be for you to share a link with a friend and they don’t even need to create an account to view your code editor/edit the site? I mean, no one will practically use such a feature, probably. But I always liked that about Google Docs, all the anonymous cursors. Why can’t we do the same? Why not have those same cursors on your actual website, too, even? ↩